
슈퍼컴퓨터 #2
과학기술 4차인재양성과정
데이터분석가과정
한국과학기술정보연구원 - 연구원님
5호기 슈퍼컴퓨터(누리온) 활용
Supercomputer?
- 범용 컴퓨터로 풀 수 없는 큰 문제럴 더 빠르고, 더 정확하게 계산하는 컴퓨터
-당대의 기술로 가능한 최고 성능의 컴퓨터.
-절대적 기준이 없으며 상대적인 성능 비교로 순위 따져서 구분함.
TOP 500 List (www.top500.org) <- 이 500위 순위 안의 컴퓨터를 슈퍼컴퓨터라고 한다.

병렬형
- 멀티코어(매니코어) 프로세서
- 클러스터
Compute nodes - 슈퍼컴퓨터의 노드 하나 (Accelerator + Cores + Shared memory)가 노트북 하나와 동일한 셈.
Interconnection network(s)
IO and service - IO = Input and Output / Services node가 어제 로그인 노드에 접속해서 실습했던 그 로그인 노드라고 한다.
Supercomputer 성능 결정 요인
> 인트라 노드 (Intra Node)
프로세서(PC)
- Clock, CPI(파이프라이닝, 슈퍼스칼라, FMA, Vector 연산)
메모리
- 계층 구조 (L1/L2/L3 캐시), 대역폭
> 인터 노드 (Inter Node)
네트워크(Network)
결국 슈퍼컴퓨터 인트라노드의 CPU하나가 데스크탑 하나인 셈이고 성능도 큰 차이 없지만
이 CPU를 여러개 붙여서 네트워크로 연결했기 때문에 이 프로세서 성능이 슈퍼컴퓨터의 성능에 영향을 주고
프로세서 성능은 CPI에 크게 좌지우지된다. (학부때 배운 컴퓨터구조수업..)
https://en.wikipedia.org/wiki/Cycles_per_instruction
현재 우리가 쓰는 프로세서는 스칼라 프로세서.
과거에는 벡터프로세서를 썼지만 스칼라 프로세서를 여러개 병렬연결하는 것이 성능도 좋고 가격도 저렴해 벡터 프로세서가 사라짐.
요즘 나오는 프로세서들은 스칼라 프로세서지만 과거처럼 큰 벡터 연산이 되지 않는데, 이 벡터 연산이 부분적으로 추가되고 있다.
캐시 : 성능이 좋은 메모리. 램하고 메모리 사이에 캐시 메모리가 있다. 그 중간에 데이터가 거쳐가는 구간으로, 데이터 이동 속도를 높임.
프로세서에 가까운 쪽이 L1. L1, L2는 프로세서 안에 있고 L3는 프로세서 밖에 있는데, L3는 없는 경우도 있다고 한다.
> Flops (floating-point operations per seconds)
- 초당 수행할 수 있는 (배정도) 실수(floating-point) 연산 회수
- 단일 노드에 대한 이론 성능 Flops 계산
Flops = (#of cores) *Cycles/second *Flops/cycle
ex) Flops/cycle = 8(AVX512:Vector) * 2 (FMA) * 2 (VPU) = 32
flops 계산 방법을 안다면 컴퓨터 정보를 보고 거꾸로 연산해볼 수도 있다.
Xeon Gold 6148 20C 2.4GHz (https://www.top500.org/system/179086)
14080 *2.4 (GHz) * 32 = 1,081,344 Gflops = 1081.344 Tflops
14080/40 = 352 nodes ( 40 = 물리적인 코어 수)
TOP500은 매년 6월, 11월 2차례 발표 (https://www.top500.org)
성능평가기준 : LINPACK 벤치마크
- LINPACK이라는 프로그램으로, N by N 행렬로 구성된 연립방정식의 해를 구하는 성능을 Flops로 표시 (선형대수 행렬계산)
- 벤치마크 코드를 돌려서 나온 flops로 성능 순위를 매긴다.
5호기 시스템 접속 - 노드 구성
| 호스트 명 | CPU Limit | 비고 | |||
| 로그인노드 | nurion.ksc.re.kr | 20분 |
ssh/lscp/sftp 접속 가능
|
||
| Datamover 노드 | nurion-dm.ksc.re.kr | - | |||
| 계산노드 | KNL | node[0001-8305] | - | ||
| CPU-Only | cpu[0001-0132] | - | |||
Module
module 명령어로 사용 가능한 모듈, 환경을 살펴볼 수 있고
필요에 따라 추가 제거가 가능하다.
module avail : 현재 사용 가능한 환경들을 보여준다
module list : 현재 접속한 내용 보여줌. 적재된 모듈 파일 확인
module add : 원하는 환경 추가
module rm : 필요없는 모듈을 내리는 명령어
KNL Architecture
Tile 하나에 코어2개 VPU2개 공유하는 구조.
MCDRAM은 Cache로도(노말큐), RAM(플랫큐)으로도 쓸 수 있다.
L1안에 A1~A4, A5~A16까지는 L1 밖에 있다면 코딩을 할 때도 A1다음 바로 A16으로 접근하게 하는 게 아니라
A1다음 A2에서 연산하고, 3으로 넘어가는 식으로 연속적으로 접근하도록 코드를 짜는게
같은 코드일지라도 내부적인 연산 속도에 차이가 난다. 캐시메모리가 찾아가는데 속도 차이가 난다?
프로그래밍에 익숙해질 수록 성능을 내기 위해 컴퓨터의 하드웨어적인 부분에 대한 이해가 필요해진다.
Compiler & Instruction Set Architecture [ISA]
Fronted + Optimazer + Backend
Fronted : 어휘분석, 구문분석, 의미분석, 중간코드 생성
- 소스코드 파싱, 에러체크
Optimizer : 최적화
Backend : target architecture에 맞는 instruction set으로 매핑하고 machine code 생성
다양한 언어(N)와 다야한 아키텍처(M)에 대해 N*M개의 컴파일러 필요
호환성의 문제.
JAVA같은 범용적인 컴파일러기반의 경우 여러 기반에서 다 사용 가능한건 그만큼 속도가 느려지고
C, Fortran처럼 특정 컴파일러와만 호환되는 것은 속도가 빠르다.
CPU에서 돌아가게 만든건 GPU에서 돌아갈 수 없다던지의 호환성 문제.
최적화라는건 그만큼 호환성과는 반대되는 말. 호환성이 좋다는 말은 성능이 떨어진다는 것 역시 의미한다.
하드웨어가 다르게 되면 바이너리, 즉 실행 프로그램이 달라지므로 컴파일을 다르게 해야한다는 말.
프로그램(exe 등)을 윈도우에서 클릭해서 실행이 되는 순간 더이상 디스크가 아닌
메인메모리에 올라가서 프로세스가 된다.
프로세서는 CPU.
진행되는 프로세스가 프로세서에 올라가서 하나하나 명령어가 CPU에 의해 실행되며 프레임이 돌아가는것.
용어가 잘 구분되어야 한다.
스레드(thread)는 프로세스의 하위개념. 프로세스 안에는 처리되어야 하는 명령어의 흐름이 있는데 그걸 스레드라고 한다.
프로세스 안에 스레드를 여러개 만들 수 있고, 그 연결된 스레드들이 동시에 처리되게 할 수 있다. 그게 스레드 병렬화.
하지만 이 스레드들을 하나의 CPU에서 실행하면 의미가 없다. 하나의 CPU에는 기본적으로 하나의 스레드가 처리된다.
병렬이 의미가 있다는 것은 이 스레드들이 다른 CPU에서 돌아간다는 것. 이게 멀티코어의 이유.
예전에는 하나의 코어가 여러 프로그램을 짧게짧게 왔다갔다하며 실행해 우리가 느끼기에는 동시에 진행되는 것처럼 느끼게 했다.
즉 결과적인 처리 속도는 동시에 처리하나 하나 처리하고 나머지 하나를 하나 똑같기 때문에 의미가 없었는데
실제로 멀티코어를 사용해 병렬처리를 진행하면 총 처리 속도에 차이가 나므로 유의미하다.
thread로 병렬화를 했을 때 물리적인 코어개수가 같아야(?) 성능이 좋다. 코어를 나눠쓰면 성능이 나쁘다.
병렬을 스레드기반으로 나누는 것 외에 프로세스 기반으로 나누는 방식이 있다.
스레드는 프로세스가 있는 노드 내에서만 돌아갈 수 있찌만 프로세스는 다른 노드에서도 만들 수 있기 때문에
한 노드에서 성능을 높이려면 스레드 병렬을 사용하지만
여러 노드에 걸쳐서 병렬작업을 진행하려면 스레드기반이 아닌 프로세스 기반이 되어야 한다.
-> OpenMP병렬 (스레드병렬)에 대해서는 다음주 월요일에 설명할 예정.
-> MPI (프로세스병렬)은 수요일에.
캐시는 메인메모리에서 필요한 데이터를 가져갈 때 하나만 가져가는게 아니라 붙어있는 연속적인 데이터를 다 가져가고
그걸 프로세스로 올릴 때 필요한 하나만 가져가서 쓰는 방식.
KNL Memory Modes ( 이것도 오른쪽에 사진 붙이자)
캐시 모드
- default
- MCDRAM은 L3 캐시처럼 동작
플랫 모드
- MCDRAM과 DDR4 는 RAM처럼 동작
: numactl 명령
: memkind/autobw library
-다른 NUMA nodes
혼합 모드
- MCDRAM은 다음과 같이 동작
: L3 cache
: DDR
누리온은 대부분이 캐시모드이고 일부가 플랫모드로 되어있는 형태.
누리온에서 numactl -H를 실행해보면 위 실행결과창처럼 두개의 노드가 연결되어있음을 볼 수 있다.
quadrant + flat : NUMA 라고 한다.
Basic Environment
여러사람이 공용으로 쓰는 슈퍼컴퓨터다보니 용량에 제한을 준다.
| 구분 | 디렉터리 경로 | 용량 제한 | 파일 수 제한 | 파일 삭제 정책 | 파일 시스템 | 백업 유무 |
| 홈 디렉터리 | /home01 | 64GB | 100K | N/A | Lustre | O |
| 스크래치 디렉터리 | /scratch | 100TB | 1M |
15일 동안 접근하지 않은 파일은 자동 삭제 |
X |
홈 디렉터리에서 파일 제출이 되지 않도록 제한되어 있다.
홈 디렉터리는 용량 및 I/O 성능이 제한되어 있기 때문에, 모든 계산 작업은 스크래치 디렉터리에서 이루어져야 함.
그리고 스크래치에서 아웃풋 파일이 나오면 15일 이내로 로컬PC 등에 다운로드 받아야 파일이 삭제되지 않는다.
즉 위에서 확인한 것은 서로 다른 로그인 노드를 사용하더라도 home과 scratch directory를 공유하고 있다,
즉 home directory와 scratch directory는 모든 노드에서 공유된다는 점이다.
일반적인 로컬에서는 서로 다른 물리적인 노드를 사용하므로 공유되지 않는다.
Compiler
- 순차 프로그램 컴파일 (시리얼)
기상청에서는 주로 Cray 컴파일러 사용
- 병렬 프로그램 컴파일
OpenMP 컴파일
-OpenMP는 컴파일러 지시어만으로 멀티 스레드를 활용할 수 있도록 개발된 기법
-컴파일러 옵션을 추가하여 병렬 컴파일을 할 수 있다.
>> Intel compiler : -qopenmp
>> GNU : -fopenmp
>> Cray compiler -homp
위 옵션이 병렬로 만들어주는 명령어이며 이게 없으면 시리얼과 사용이 동일하다.
MPI 컴파일
- MPI 명령을 이용하여 컴파일
- MPI 명령은 일종의 wrapper로써 지정된 컴파일러가 소스를 컴파일한다.
mpi는 사용은 시리얼과 동일한데 맨 앞 명령어가 다르다.
Job Scheduler : PBS
PBS가 노드들을 계속 모니터링 하면서 사용자가 제출하는 job script를
들어온 순서에 따라 실행시키거나 대기시키는 스케줄러의 역할을 한다.
또는 순서뿐 아니라, 현재 비어있는 노드가 50개인데
먼저 들어온 A가 필요한 노드는 100개이고 그 다음 제출한 B가 필요한 노드가 50개라면 B를 먼저 처리해주는 등 조율을 담당한다.
큐 정책
큐 조회
- showq, pbs_status
qstat
-Q : queue 목록 조회
-f : queue 상세 정보 조회
순차코드 예제 [Pi 계산]
walltime은 아까 앞에 설명한 스케줄러가 Priority를 부여하는 데 고려대상이 된다.
그만큼 wallclocktime은 중요하므로 필수적이고, 즉 본인의 작업이 대략 어느정도 걸릴지를 알고 있어야 한다.
#PBS -A etc 는 PBS가 필요한 건 아니고, 관리자가 사람들이 주로 어떤 프로그램..컴파일러?를 쓰는지 궁금해서 자료 뽑을 목적으로 넣은거
사용자작업은 계속 말한대로 "반드시" /scratch 에서만 제출이 가능하다.
- qsub {job_script_name}
제출된 작업을 삭제할 수도 있다. qsub 이후 뜨는 pbs가 작업ID이다.
- qdel {JOBID}
실행 및 대기중인 작업 조회
- qstat
- qstat -u "계정명" : 지정 계정 작업 목록 출력
실행 완료 된 작업 확인
- qstat -x (u옵션 사용은 동일)
ls를 하면 작업되는 Jobname과 JobID로 e, o 파일 즉 각각 두개의 파일이 새로 생성된 것을 볼 수 있는데
e에는 에러파일이 나타나고 o에 실행된 내용이 저장된다.
컴파일(pi.c)
위는 KNL로 컴파일한 예제이다.
빌드가 되었다면 이후 serial.sh파일 마지막에 ./pi_serial_vec 실행파일을 추가하고 아까와 동일하게 qsub한다.
아까 처음 돌린 것과 방금 craype-mic-knl 모듈을 사용해 KNL 노드를 사용한 작업 시간을 확인하면
확연히 시간이 짧아진 것을 확인할 수 있다.
컴파일(piOpenMP.c)
이번에는 동일한 KNL노드를 사용하는데 openmp코드를 짜 본다.
ncpus에서 34개 또는 68개를 잡아도 되고 그 뒤에 thread는 앞에 잡은만큼 또는 더 적게 써도 된다.
여기선 34개를 잡고 34개를 사용해 주었는데 아마 68개를 잡고 68개 쓰면 속도가 다르게 나올 것.
컴파일(piMPI.c)

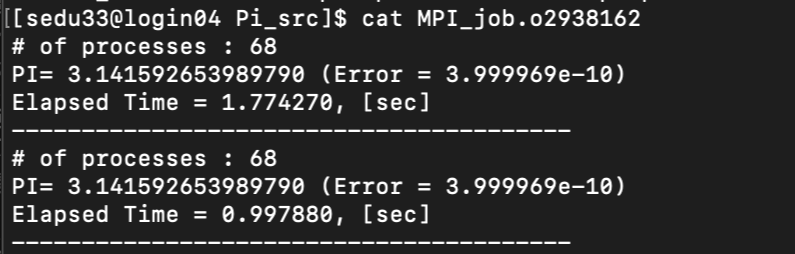
thread를 1로 하고 procs를 68개 즉 프로세스가 여러개 잡힌것이다.
컴파일(piHybrid.c)
#PBS -l select=2:ncpus=68:mpiprocs=2:ompthreads=34
2개의 물리적인 코어를 잡고 프로세스를 2개를 잡아서 총 프로세스가 4개로 나온다.
그리고 68개를 잡았지만 실제 사용 스레드는 34로 지정했기 때문에 4개의 프로세스 각각에 34개의 스레드가 동작한다.
PBS Interactive 작업 제출
누리온 시스템은 debug노드 대신 debug 큐를 제공
degug 큐를 이용하여 작업을 제출함으로써 디버깅 수행이 가능하다.
> qsub -I (대문자 i)
>>핵심요약<<
슈퍼컴퓨터를 사용하는데 핵심은 스케줄러를 사용하는 것.
로그인노드로 들어와서 스크립트 파일로 필요한 만큼 노드를 잡아 스케줄러에게 스크립트를 던져 작업을 수행하는 것.
여러 사람이 사용하는 것이기에 필요 노드 수와 러닝타임에 따라 Priority가 달라진다는 것.
스케줄러는 오늘 사용한 것 외에 다른 것도 있지만 명령어들이 조금 다른 것 외에 기본적으로 필요한 정보, 받는 정보는 동일하다.
mapping되는 키워드만 조금씩 바꿔주면 기본적인 과정은 동일하다.