과학기술 4차인재양성과정
데이터분석가과정
한국과학기술정보연구원 이홍석, 정희진 연구원님
인공지능은 기존 학문과 다르기 때문에 다른 접근방법이 필요하다.
텐서플로우 실습 위주로 진행할 것
개발자 - 개발만 하다가 커리어 관리가 안된다 (박사 이야기일듯. 논문 써야 할 때 못쓴다)
요즘은 새로운 기술, 논문이 나오면 코드도 다 공개되어서 일주일 공부하면 전문가가 될 수있다.
하지만, 모두가 전문가라는 뜻이다. 그래서 우리의 환경이 열악하다고 하심.
하나만 잘해낸 뒤에 6개월만 방심하면 그 기술이 굉장히 평범해진다.
이에 대해 우리 스스로 답을 찾아야 한다.
실습자료 중 project라고 넣은 이유 : 하는 방법을 알려주기 위해서.
박사님이 정부에 오퍼해서 진행중인 교통정리 데이터 - 저렇게 접근하는 사람이 잘 없기 때문에 잘 해낸다면 여전히 경쟁력 있는 기술 시장
깃허브들에 정보는 많은데 그걸 어떻게 본인 것으로 만들 것이냐가 중요함.
---------
인공지능 및 인공신경망
인공지능 1차 암흑기(Sigmoid ) - 2차 암흑기(Back propagation - 여전히 학습할수록 값이 사라져서 학습 불가) - 딥러닝 (Relu로 해결 - 미분해도 상수. 값이 사라지지 않음.)
깊은 층을 계산 가능하게 하냐, 아니냐.
깊은 층을 계산하게 했을 떄 달라지는 점 - 정확도가 높아짐.
딥러닝 성능이 좋냐 안좋냐의 기준 :: 사람. 평균적인 사람이 내는 오류와 비교했을 때 더 좋은가 아닌가가 기준이다.
왓슨 제퍼디쇼 우승, 알파고 바둑 우승, 알렉사, CES장악 등이 딥러닝이 사람을 뛰어넘었는지를 알아보기 위한 것. 인공지능이 사람보다 우수한 분야를 찾아나가고 있다.
현재 딥러닝이 사람보다 우수하게 해결한 문제가 많지 않다. 예산과 시간 투자가 된 것에 비해 - 딥러닝 기술이 그렇게 많지 않음. 해결되지 않으면 3차 암흑기가 올 것이다.
딥러닝은 잘 들어다보면 기존의 인공신경망과 다를바가 없다. 하지만 활성함수(activation function)를 바꿔줬더니 (Relu) 사람보다 좀 더 나은 성능을 내더라. 딥러닝이 만능이거나 모든 분야에 우수한 것은 아니라는것.
실습파일을 실행할 건데 이전 수업에 깔아둔 아나콘다에서 텐서플로우를 이용하려 한다.
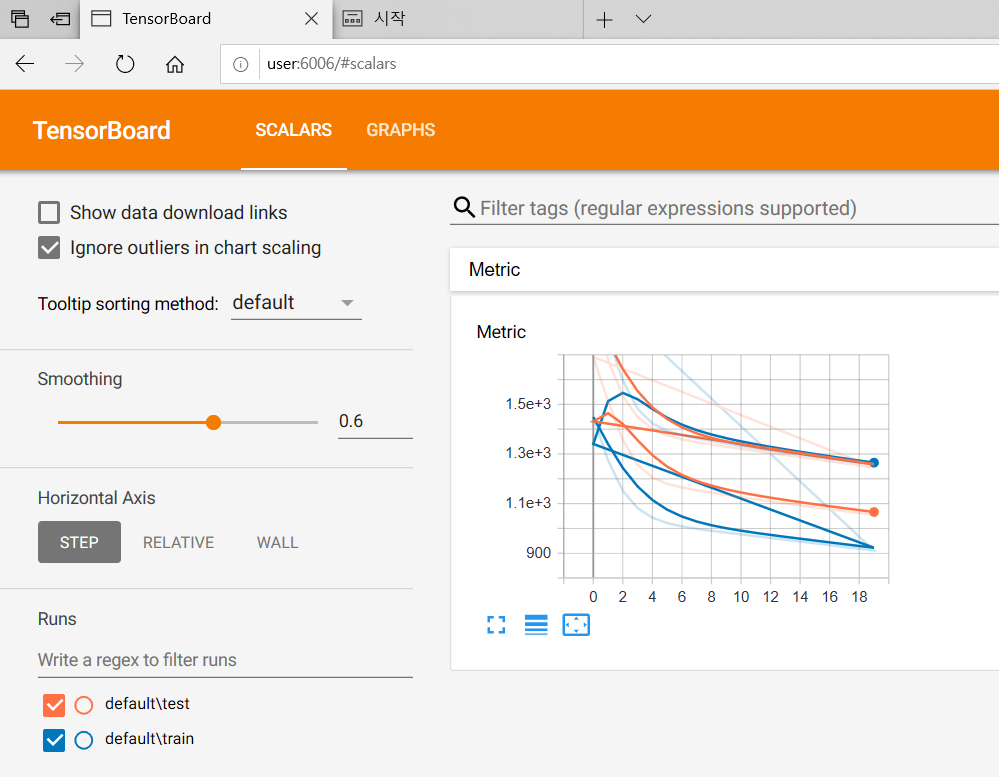
교통 현황 시계열데이터로 예측하기
LSTM으로 음악 작곡,실행 - 나비야
-----------------------------------------------------------------------

정희진
한국과학기술정보연구원
빅데이터의 의미에는 '쓰레기 데이터'라는 의미 역시 내포되어 있다.
서로 다른 목적을 갖고 각기 다른 곳에서 수집된 정보들이 모인 것이기 때문에, 예전에는 활용되지 못하고 버려졌다.
4차 산업 혁명 키워드 : 지능화, 초연결성, 개인화, 융합
빅데이터 분석가의 기본 소양 : 스토리 텔링. 거짓말을 잘 하는 사람(ㅋㅋ)
일반적인 과학 데이터는 통계적으로 정확한 의미를 갖고 분석해낸 데이터가 가리키는 곳만 정확히 따라가면 되지만
빅데이터는 그들의 입장에서 보기에는 정돈되지 않은 의미없는 데이터. 큰 트렌드를 잡아내는데에는 통계학 분석을 쓸 수 없다.
그래서 초기 빅데이터는 통계학자가 분명 주도하였으나 빅데이터를 분석하는 데에는 적절하지 않기에 도태되는 상황.
빅데이터에서 평균은 아무 의미 없다.
데이터의 트렌드, 데이터에서 하나의 값을 뽑아낸다는 것은 의미가 없다.
예전 시각화는 한 숫자로 요약하는 방식으로 간다면
빅데이터는 데이터 있는 흐름 그대로를 시각적으로 나타내는 데에 중점을 두고 있다.
빅데이터의 수혜자가 바뀌었다.
예전에는 상위 극소수의 의사결정권을 위해 사용되었다면 최근에는 모든 사람이 데이터를 활용하는 시대. - 초연결성
빅데이터 분석가가 된 사람들의 목적이 달라졌다.
이전 결과물은 F Value, P Value 등 전문가만이 알 수 있는 스킬이 요구되었다면
지금은 초등학생도 알 수 있을 수준으로 아웃풋이 잘 나와야한다. 시각화를 잘 해내야하고 색감, 보기 쉬운 도식화 등을 활용해
분석 자체도 중요하나 ( 기계적인 분석법은 이미 도태되었음. 분명 더 정확하나 데이터의 순도에 매우 민감하므로 잡데이터인 빅데이터에는 알맞지 않다)
비전공자가 한눈에 보기에도 결과물이 매력적이고 납득할 수 있을 만한 것을 내놓아야한다.
Process of data based intelligent systems
Data collection - Data Storage - Data aAnalysis - Intelligent Services
Data collection
IoT의 교통 버전이 Connected Vehicle
Data Storage
하둡이 나타나면서 이 분야가 떴음
Data aAnalysis
AI가 데이터 분석가의 직관력을 얼마나 따라갈지가 관건.
다만 AI는 공장제가 아니라 전문가가 직접 적합한 모델들을 가져다 본인만의 스킬로 만들어내는 것이므로
그것이 데이터 분석가 본인의 포트폴리오가 된다면 경쟁력이 있을 것이다.
큰 기업들이 이미 인공지능, 빅데이터 시장을 선두하고 있는데 왜 회사가 투자를 해야 하냐?
-> 99개의 목적이 있다면 그에 맞는 모델도 99개가 필요하다.
AI를 만드는 일 자체가 데이터 분석가가 필요한 자리이다.
Intelligent Services
Smart City
지금까지 나온 스마트시티는 다 가짜이다. 앞의 세 개가 된 게 없으니까.
스마트시티를 먼저 만들고 앞의 세 개를 하려니 될 리가 없는 것.
Data Open하는 곳이 늘고 있다 - 그렇다면 데이터를 활용할 사람이 늘 것. 왜 공개할까.
이런 대기업들이 콘텐츠 생산 능력이 안 생기는 것.
콘텐츠를 가져가서 창의력 있는 서비스 만드는 것을 지켜보고 나중에 그 아이디어들을 골라 사용하겠다는 것.
데이터가 있으면 아이디어가 상상에 그치지 않고 실제 서비스화 될 수 있다.
개발자로 가려면 아나콘다 말고 파이챰을 써라
아나콘다는 오픈소스라 질이 조금 떨어짐. 아나콘다의 스파이더도 괜찮기는 함.
파이챰이 작년부터 아나콘다에 붙어서 아나콘다에서 오픈 가능하긴 한데 그래도 파이챰,,
파이썬을 배워라.
:: 교통정보의 개념
정보의 정의
data : 아직 특정의 목적에 대하여 평가되지 않은 상태의 단순한 여러 사실
정보(Information): Data를 수집, 정리, 분석하는 가운데 단순한 사실에 인간이 의미를 부여한 것
-수신자(recipient)에 의미가 있는 형태로 처리된 Data
-현재 또는 미래의 행위나 의사결정에 실제 또는 지각된 가치를 가진 Data
정보의 특성
-남에게 전하거나 판매해도 줄어들지 않음
-대량 생산이 필요 없음
-하나의 정보로 모든 수요의 충족이 가능
-새로운 정보를 생성할 수 있음
교통
정보의 교환. 정보의 흐름 다 포함된다. 교통 정보는 움직이는 정보이기에 휘발성이 강하다.
정보의 제공 시점
-통행 전(pre-trip) 정보 : 통행시간, 최적경로 등
-통행 중(en-route)정보 : 도착시간, 사고정보 등
정보의 생산시점
-정적인 정보 : 거의 변하지 앟는 정보
-실시간 정보: 지속적으로 변하는 정보
정보의 성격
-설명적 정보: 이요자에게 일방적으로 의사결정 및 변경을 강요하는 정보 (최적경로)
-권고적 정보: 이용자의 자유로운 의사결정을 유도하는 정보 (우회경로 안내)
교통정보의 역할

오픈소스를 사용할 때 주의 할 점 , 데이터 를 사용하는 사람들은 최신 버전 쓰는 것을 지양해야 한다.
최신버전이라는건 버그가 많다는 뜻이고, 특히 오픈소스라면 그런 것의 피드백/수정이 즉각 이루어지지 않는다.
상용 소프트웨어라면 그런 피드백은 즉각적이겠지만,,
공간자료란
: 벡터자료 와 래스터자료. 벡터자료는 확대해도 깨지지 않음. 축소해도 보이진 안하도 정보 다 포함함.
래스터 이미지는 처음에 이 정보를 제작했을때 설정한 해상도를 유지하면서 하기 때문에 확대를 과도하게 하거나 축소를 할 경우 화질 저하가 일어남. 정보의 질은 래스터가 좀 더 우수하고 정보의 질을 유지하기에는 백터가 유리하다.
해외는 좌표계가 거의 통일되어있다시피 하고 좌표와 그에 대한 설명이 잘 제공되나
우리나라는 좌표계가 통일되지 않고 회사마다 개인마다 중구난방으로 사용해서 업무에 통일이 안되는 경우가 다반사임.
강사님의 '한국 주요 좌표계 EPSG코드 및 proj4 인자 정리' 텍스트문서에 정리해 둔 이유.
주요 좌표계 정도는 알아두는 것이 좋다.
공간 자료의 획득
- 국토정보플랫폼 (map.ngii.go.kr)
- 통계청 통계지리정보 (https://sgis.kostat.go.kr)
SHAPE 파일
ESRI가 개발한 벡터 데이터 포맷. GIS에서 가장 널리 사용되고 있는 벡터 데이터 파일 형식.
Shape 파일은 필수 파일이 있다
- *.shp 객체의 기하학적 정보가 저장된 파일
- *.shx 객체를 빨리 찾을 수 있또록 인덱스가 저장된 파일
- *.dbf 속성정보가 dbASEIV 형태로 저장된 파일
다음과 같은 추가 파일이 있을 수 있다
- *.prj 좌표계와 투영 정보가 저장된 파일
- *.sbn 객체를 빨리 찾을 수 있또록 인덱스가 저장된 파일
- *.shp.xml 공간 메타데이터를 XML 형태로 저장된 파일
GIS를 잘 활용하면 보고서를 쓰는 데에도 매우 유용하다.
맵끼리 레이어링도 되고...컬러 필터도 입힐수있고...
우리가 여기서 배우는 목적은, 도메인 분석가가 아니다. 강사님도 데이터 분석가라고 하지만 '교통'데이터 분석가인 것처럼
전문 분야가 있는 사람들임. 랩실가서 지식이 쌓여야 가능하고
우리의 교육은 기초적인 빅데이터 전문가를 목적으로 하기 때문에 도메인에 구애 받는게 아니다.
그래서 스스로 여러 타입의 데이터를 다루어 보아야 한다. 차량의 GPS, 매출정보, 어획량, 아파트 시가...
이런 데이터들을 막 다뤄보는 연습을 해야 한다. 어디서든 쉽게 구할 수 있는 데이터들임.
분석해보고, 지도에 표출도 해보고. 이왕이면 현실 적용도 높은 쪽으로. 누군가의 그런 데이터 분석 보고서가 있다면
어떻게 표현했고 어떻게 해석했는지를 잘 보고 자기 포트폴리오 자기 스크립트를 만들어야한다.
물론 취업해서 자기 분야를 쌓는게 제일 좋지만 그게 안된다면 이런 식으로라도 경험을 쌓아보는 것.
-----------------------
아나콘다 패키지는 귀찮더라도 환경 만들어서 env에 깔지 base에는 기본적인 것만 깔아두어야 한다.
업데이트가 진행되면서 환경과 베이스의 버전이 맞지 않는 경우가 있기 때문
파이썬 - 얕은 카피 깊은 카피
a = A에서
값 전체를 할당받는 것과
a가 원본인 A의 위치만 할당받는 것
원본 데이터가 바뀌어버리는 일이 생기기 때문에 얕은 카피가 아니라(a=A 등호쓰는게 얕은카피)
깊은 카피를 만들어서 원본 데이터를 건드리지 않고 아예 다른 공간에서? 처리를 하겠다는거. 아닌데 잠만 이게 얕은 카피라고/?
얕은 카피로 여러개 카피해서 하나를 바꾸면 나머지도 다 바뀌어버려서 데이터 처리하는 사람이 파이썬을 잘 모르면 실수 많이 한다.
데이터 위치 참조만 해서 그걸로 계산 해서 다른 변수로 저장해버리면 편함. 이거는 얕은 카피의 장점.
데이터 전처리 할 때는 웬만해선 얕은 카피를 하면 안된다.
a = copy.deepcopy(A)
깊은카피 하는 방식
컬럼을 맞춰두는 것. 원본 데이터의 컬럼 이름이나 순서를 참조하기 위해서는 DF.columns로 불러와서 따로 변수에 저장해두는 것을 추천.
컬럼을 합치기도 하고 순서 변경도 하고 인덱스로 넣었따 뺐다 하면서 순서가 엉켰을 때 원본과 대조하여 복구시킬 수 있어야 하므로
'KISTI 빅데이터 분석가 과정 > 데이터분석' 카테고리의 다른 글
| 재난재해 데이터 #2 (0) | 2019.07.23 |
|---|---|
| 재난재해 데이터 #1 (0) | 2019.07.22 |
| 천문데이터 #4 (0) | 2019.07.18 |
| 천문데이터 #3 (0) | 2019.07.17 |
| 천문데이터 #1, #2 (0) | 2019.07.15 |
